 国际站
国际站 影响因子(Impact Factor, IF),无疑是当今学术界最有影响力的期刊评价指标。它如同上市公司的“股价”,一个简单明了的数字,却深刻地影响着期刊的声望、作者的投稿选择,乃至科研人员的职业晋升和经费申请。
然而,当整个学术圈都对高IF期刊趋之若鹜时,我们有必要冷静地提出一个根本性问题:一个期刊的高影响因子,真的能完全代表其上每一篇论文的高质量吗?
答案,远比一个简单的“是”或“否”要复杂。
第一部分:影响因子 (IF) 是如何计算的?
要理解它的局限,首先要明白它的来源和算法。
- 发布机构: 科睿唯安(Clarivate)
- 数据来源: 《期刊引证报告》(Journal Citation Reports, JCR)
- 核心算法(以2024年影响因子为例):
IF (2024) = 该期刊2022年和2023年发表的所有“可引证项目”,在2024年被引用的总次数 ÷ 该期刊在2022年和2023年发表的“可引证项目”总数
通俗地说,它衡量的是一本期刊在过去两年发表的论文,在第三年的“篇均被引次数”。
第二部分:为什么高IF备受追捧?
高IF之所以成为学术界的“硬通货”,主要有以下原因:
- 简单直观: 它将一本期刊复杂的学术声誉,简化成了一个可以轻松比较的数字,满足了快速评价的需求。
- “光环效应”: 在高IF期刊(如 Nature, Science, The Lancet)上发表论文,本身就是对作者科研能力的一种巨大肯定,能带来极高的学术声望。
- 现实世界的“指挥棒”: 在全球许多科研评价体系中,高IF论文的数量和质量,直接与学位获取、职称评定、基金申请、人才引进等核心利益挂钩。
第三部分:“高IF ≠ 高质量” — 影响因子的五大核心局限
现在,我们来回答核心问题。为什么说高IF不直接等于一篇具体论文的高质量?
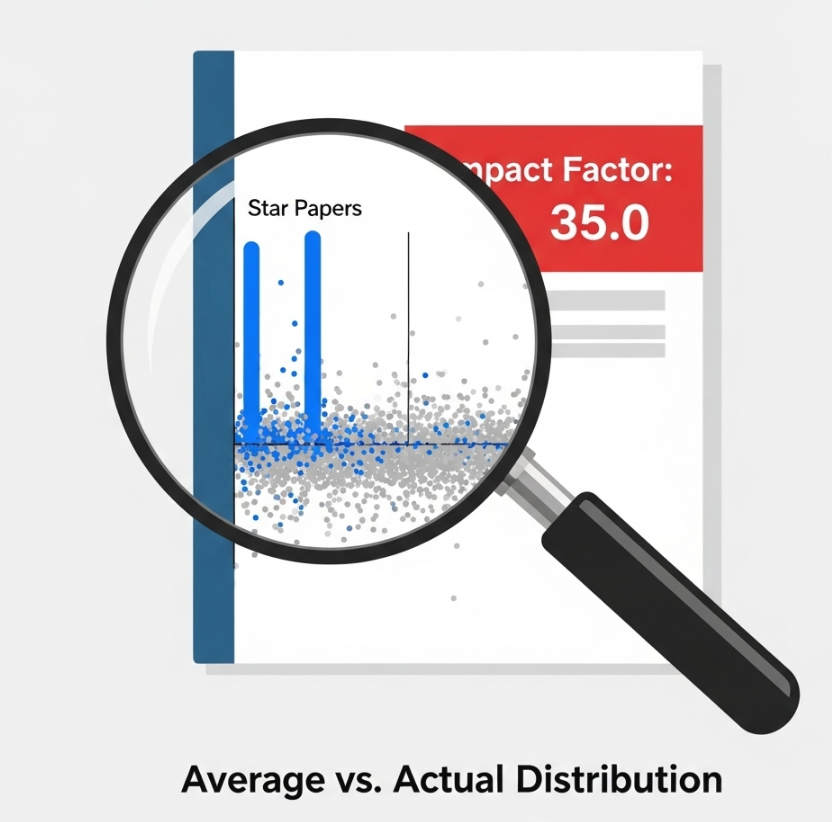
1. “平均数”的陷阱:引用分布极度不均
这是IF最根本、最致命的缺陷。 一本期刊的高IF,往往是由极少数几篇“爆款”高被引论文拉动的,而该期刊上绝大多数的普通论文,其被引次数可能远低于这个平均值。
- 一个生动的比喻: 一个房间里有99个普通人和1位亿万富翁,这个房间的人均资产会高得惊人,但这个“平均数”能代表那99个普通人的真实财富状况吗?显然不能。
2. 学科间的“不公平”比较 不同学科的科研人员数量、研究周期和引用习惯天差地别。
- 例如: 生命科学领域,研究人员众多,成果迭代快,引用密度高,其顶级期刊的IF动辄三四十。而数学或某些工程领域,研究周期长,一篇论文的价值可能需要数年才被认可,其顶级期刊的IF可能只有3-5。用IF数值直接跨学科比较,是完全没有意义的。
3. 短视的“两年”窗口期 IF只统计过去两年的论文引用。这极大地偏向了那些能快速产出、快速引用的“短平快”热门研究,而忽视了那些需要长时间沉淀和验证的、具有开创性的基础理论研究。
4. “可引证项目”的定义模糊 期刊编辑可以通过一些“操作”,来提升IF。例如,将社论、新闻等类型的文章定义为“非可引证项目”,让它们不计入分母;但这些文章获得的引用,却有可能被计入分子,从而人为地推高了IF的数值。
5. “自引”与“抱团引用” 部分期刊可能会通过鼓励作者引用本刊文章(自引)或与其他期刊形成“引用联盟”的方式,来不当提升自己的IF。
第四部分:超越IF — 如何更全面地评估一篇论文?
既然IF有如此多的局眼性,我们应该如何更科学地评估一篇论文的价值?
- 1. 回归论文本身 阅读论文本身,永远是最终的、最可靠的评判标准。 它的研究问题是否重要?方法是否严谨?论证是否清晰?结论是否可靠?
- 2. 参考期刊分区 (Quartile) 相比于IF的绝对数值,期刊分区(Q1, Q2, Q3, Q4)是更科学的相对指标。它代表了一本期刊在其所属细分领域内的相对排名。一本Q1分区的期刊,意味着它是该领域影响力排名前25%的刊物,这比一个孤立的IF数字更有说服力。
- 3. 结合其他评价指标
- Scopus的CiteScore: 采用4年时间窗口,数据更稳定、透明。
- Google Scholar的h5-index: 衡量了出版物在过去5年的核心高引产出。
- 4. 关注作者与机构的声誉 一篇由领域内知名学者或顶尖研究机构发表的论文,其可信度通常更高。
结论 回到最初的问题:高IF真的等于高质量吗?
一个负责任的回答是: 一本高IF的期刊,无疑是一个竞争激烈、声望卓著的发表平台,它更有可能发表高质量的论文。但是,IF分数并不能为该期刊上的任何一篇具体论文的质量提供“担保”。
作为一名成熟的研究者,我们应该将影响因子看作一个有用的、但充满局限的参考工具,而不是盲目崇拜的“黄金标准”。真正重要的,是培养起自己对一篇研究工作内在价值的独立判断能力。